



Trong thế giới Excel hiện đại, việc phân nhóm dữ liệu một cách linh hoạt và tự động là yêu cầu ngày càng phổ biến — và đó chính là lý do hàm GROUPBY ra đời. Được giới thiệu trong bộ hàm mới của Excel 365, GROUPBY cho phép bạn nhóm dữ liệu theo một hoặc nhiều tiêu chí, đồng thời thực hiện các phép tính tổng hợp (như đếm, cộng, trung bình...) mà trước đây bạn phải dùng đến Pivot Table, Power Query hoặc công thức phức tạp mới làm được.
Bài viết này sẽ hướng dẫn bạn một cách toàn diện: từ khái niệm, cú pháp, cho đến những ví dụ thực tế, các mẹo kết hợp GROUPBY với những hàm khác, và ứng dụng nâng cao trong phân tích dữ liệu. Dù bạn là người mới hay đã quen với Excel, việc nắm vững GROUPBY sẽ giúp bạn xử lý dữ liệu nhanh chóng, chính xác và chuyên nghiệp hơn bao giờ hết.
1. Cú pháp hàm GROUPBY
=GROUPBY(row_fields, values, function, [field_headers], [total_depth], [sort_order], [filter_array], [field_relationship])
Ý nghĩa các tham số của hàm GROUPBY:
Bảng tham số hàm GROUPBY
| Tham số | Bắt buộc/ Tùy chọn | Giải thích chi tiết |
|---|---|---|
| row_fields | Bắt buộc | Mảng (array) chứa các trường (fields) dùng để nhóm dòng (giống như "Group by" theo cột nào). |
| values | Bắt buộc | Mảng giá trị mà bạn muốn thực hiện phép tính (như cộng tổng, đếm, trung bình...). |
| function | Bắt buộc | Hàm áp dụng: "SUM", "COUNT", "AVERAGE", "MAX", "MIN", hoặc LAMBDA. |
| field_headers | Tùy chọn | Tiêu đề cho các cột kết quả. |
| total_depth | Tùy chọn | Mức độ nhóm nhiều cấp (ví dụ theo "Vùng" rồi "Quốc gia"). |
| sort_order | Tùy chọn | Sắp xếp tăng (1) hoặc giảm (-1). Mặc định là 1. |
| filter_array | Tùy chọn | Điều kiện lọc dữ liệu trước khi nhóm. |
| field_relationship | Tùy chọn | Mô tả quan hệ giữa các field khi nhóm phức tạp. |
Ta có thể diễn giải các tham số này dễ hiểu hơn như sau.

2. Các ví dụ thực chiến sử dụng hàm GROUPBY trong thực tế
2.1. GROUPBY đơn giản theo 1 cột dữ liệu trong Excel
Để demo phần này mình đang sử dụng khối dữ liệu như hình dưới.

Dữ liệu được sử dụng trong bài này là kiểu dữ liệu dạng Table có tên là DATA_GROUPBY.
Trong ví dụ đầu tiên này mình sẽ chọn cột ProductName và Amount để đưa vào hàm GROUPBY. Lưu ý là mình chọn dữ liệu này sẽ bao gồm cả tiêu đề.

Đây là hàm mình đã viết.
Và đây là kết quả trả về.

Giải thích 1 chút thì ở đây chúng ta chọn row_fields là cột ProductName.
Values mình lựa chọn là cột Amount.
Function được sử dụng ở đây là SUM.
Với phần field_headers thì mình lựa chọn số 3 nghĩa là yes and show.
Mặc định với phần field_headers ta có 3 lựa chọn lần lượt là: 0 – No, 1 – Yes but don’t show, 2 – No but generate, 3 – Yes and show.
Đa phần khi viết công thức GROUPBY chúng ta sẽ lựa chọn tuỳ theo công thức mà chúng ta viết.
- Nếu bạn chọn field_headers = 0 – No thì bạn đang thông báo cho Excel biết là dữ liệu của chúng ta không có tiêu đề.
- Nếu bạn chọn field_headers = 1 – Yes but don’t show thì bạn đang thông báo cho Excel biết là dữ liệu của chúng ta có tiêu đề. Tức là chúng ta sẽ lấy dòng đầu tiên trong vùng dữ liệu bạn chọn để làm tiêu đề. Ví dụ như trên thì tiêu đề lần lượt sẽ là ProductName và Amount.
- Nếu bạn chọn field_headers = 2 – No but generate thì có nghĩa là dữ liệu của bạn không có tiêu đề, lúc này Excel sẽ tự tạo ra (generate) ra 1 tiêu đề theo ý nó cho bạn. Mình khuyến khích bạn không nên sử dụng tính năng này.
- Nếu bạn chọn field_headers = 3 – Yes and show. Lúc này thì bạn đã thông báo cho Excel biết bạn có tiêu đề (dòng đầu tiên mặc định được hiểu là dòng lấy làm tiêu đề) và bạn muốn hiển thị ra nó. Đây là 1 trong các lựa chọn mình rất hay sử dụng.
Bạn có thể thấy trong công thức mình đã đưa lên trên có đoạn “DATA_GROUPBY[[#All],[ProductName]]”. Đoạn này có ý nghĩa là bạn lấy ra toàn bộ cột ProductName bao gồm cả tiêu đề.
Thường khi viết công thức trong Excel thì các bạn khi muốn tham chiếu đến cột ProductName thì các bạn sẽ viết là DATA_GROUPBY[ProductName]. Vậy 2 phần tham chiếu trên khác nhau như thế nào?
Dưới đây là tham chiếu khi bạn chọn DATA_GROUPBY có [#All] và không có [#All]
Dưới đây là tham chiếu khi bạn chọn
DATA_GROUPBY[[#All],[ProductName]]
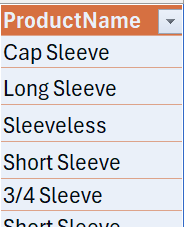
Còn đây là tham chiếu khi bạn chọn
DATA_GROUPBY[ProductName]
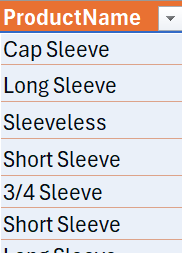
Điểm khác biệt giữa 2 tham chiếu này đó là tham chiếu bên trên sẽ bao gồm cả Header còn tham chiếu bên dưới thì không?
Vì vậy nếu ta sử dụng tham chiếu như bên dưới mà viết công thức GROUPBY thì kết quả trả về sẽ là gì?
Đây là kết quả trả về của công thức trên

Bạn sẽ thấy hơi sai sai đúng không? Tại sao lại xuất hiện Cap Sleeve là Header?
Vì dòng Cap Sleeve có giá trị Amount = 164.7 là giá trị dòng đầu tiên xuất hiện trong bảng dữ liệu của chúng ta.

Vậy trong trường hợp mình vẫn muốn sử dụng cú pháp tham chiếu riêng phần Data không bao gồm Header cho đơn giản và vẫn muốn có tiêu đề thì làm sao?
Cách đơn giản là chúng ta sẽ dùng hàm VSTACK ghép phần tiêu đề vào kết quả của hàm GROUPBY là được.
Ngoài ra với hàm GROUPBY thì mình sẽ sử dụng tham số field_headers bằng 0 hoặc mặc định là No.
Bạn sẽ viết như dưới đây.
Dưới đây là kết quả của công thức trên

Thực ra trong thực tế, khi bạn muốn tạo ra Header theo ý mình thay vì Header mặc định được sử dụng từ Header của Table dữ liệu gốc thì đây là cách bạn nên sử dụng.
Các bạn có thể thực hành các kiến thức vừa rồi với dữ liệu ở Sheet GROUPBY_01 dưới đây.
2.2. Sử dụng filter_array để lọc dữ liệu trong hàm GROUPBY
Giờ ta sẽ có 1 ví dụ như sau: Tiến hành tạo báo cáo tổng doanh thu của các Product Name với điều kiện Channel Name là Online
Trong trường hợp này thì bạn chỉ cần viết 1 filter_array đơn giản như sau:
DATA_GROUPBY[ChannelName]="Online"
Về cơ bản thì filter_array là 1 mảng 1 chiều giống hệt với tham số include của hàm FILTER.
Các bạn có thể hiểu rằng giống như hàm FILTER thì GROUPBY sẽ tiến hành lọc ra các dòng trả về kết quả TRUE hoặc 1 rồi sau đó mới bắt đầu tiến hành GROUPBY các dòng dữ liệu thoả mãn điều kiện lại.
Nếu bạn nào quen với cú pháp SQL thì phần filter_array này sẽ tương tự với việc viết điều kiện WHERE trong cú pháp SQL của bạn.
Và đây là công thức mình viết cho bài toán này.
Dưới đây là kết quả của công thức trên

Các bạn có thể thực hành với dữ liệu của Sheet GROUPBY_01 dưới đây
2.3. GROUPBY với row_fields nhiều hơn 1 cột
Trong các ví dụ ở trên các bạn đều đang sử dụng duy nhất 1 cột Product Name. Vậy nếu có nhiều cột hơn thì sao? GROUPBY có hỗ trợ hay không? Câu trả lời đương nhiên là có.
Giờ ta sẽ có 1 câu hỏi như dưới đây: Tiến hành tạo báo cáo tổng doanh thu theo cả Product Name, Channel Name.
Dưới đây là kết quả của công thức trên

Hoàn toàn đơn giản đúng không nào? Điều này có nghĩa là nếu bạn muốn nhóm nhiều cột hơn nữa thì GROUPBY cũng hỗ trợ. Bạn có thể thoải mái sáng tạo ra báo cáo của bản than mình.
2.4. Sắp xếp dữ liệu trong hàm GROUPBY
Giờ ta muốn giải quyết bài toán như sau: Tiến hành sắp xếp dữ liệu được hiển thị với cột số 1 sắp xếp giảm dần, cột số 2 sắp xếp tăng dần.
Để giải quyết bài toán này thì ta sẽ sử dụng đối số sort_order của hàm GROUPBY.
Lưu ý kỹ là đối số sort_order chỉ hỗ trợ sắp xếp 2 kiểu như sau:
- Sắp xếp nhiều cột của row_fields cùng lúc.
- Chỉ sắp xếp cột values.
Đây là lưu ý bạn cần nhớ rõ giúp mình.
Đây là kết quả mà chúng ta thu được.

Bạn có thể thấy cụm {-1,2} của tham số sort_order có thể hiểu như sau.
-1 => Tức là ta muốn sắp xếp cột row_fields thứ nhất giảm dần.
2 => Tức là ta muốn sắp xếp cột row_fields thứ hai tang dần.
Kết quả của hàm GROUPBY thu được là hoàn toàn chính xác. Vậy nếu ta muốn sắp xếp cột Amount thì làm thế nào?
Tuy nhiên trong trường hợp bạn vừa muốn sắp xếp các cột row_fields, vừa muốn sắp xếp lại phần values thì bạn sẽ cần viết 1 công thức phức tạp hơn chút như dưới đây.
Với công thức này thì mình sẽ không sử dụng header và grand total tự tạo của hàm GROUPBY mà mình sẽ tạo ra nó bằng công thức.
Việc sắp xếp các kết quả trả về sẽ thông qua hàm SORT.
Còn dòng Grand Total sẽ được tạo thông qua hàm HSTACK. Tại sao ở đây lại dùng HSTACK chứ không phải cú pháp {…} như phần tiêu đề? Lý do rất đơn giản đó là do cú pháp {…} không hỗ trợ việc sử dụng công thức trong đó. Còn HSTACK thì cho phép nên bạn có thể sử dụng HSTACK thay thế cú pháp {…} để có thể tuỳ biến tốt hơn cho công thức của mình.
Phía dưới đây là kết quả trả về.

Các bạn có thể thực hành với dữ liệu của Sheet GROUPBY_01 dưới đây
2.5. Sử dụng đối số field_relationship trong hàm GROUPBY
Đối số field_relationship trong hàm GROUPBY là 1 đối số mới được thêm vào hàm GROUPBY.
Tham số field_relationship gồm 2 đối số đầu vào lần lượt là:
0 – Hierarchy (default)
1 – Table
Mặc định field_relationship là Hierarchy (hệ thống phân cấp) là một cấu trúc tổ chức dữ liệu hoặc thông tin theo nhiều cấp bậc, từ tổng quát đến chi tiết. Mỗi cấp trong hệ thống thường là cấp "cha" hoặc "con" của cấp khác, tạo thành một dạng cây (tree structure).
1 là Table tức là dạng bảng. Vậy 0 và 1 khác gì nhau?
Ta sẽ làm ví dụ đơn giản như sau.
Dưới đây là 2 công thức sử dụng field_relationship lần lượt là Table và Hierarchy. Cả 2 công thức này mình đều sắp xếp giảm dần theo cột Amount (Cột số 3)
Sử dụng field_relationship là Hierarchy
Dưới đây là kết quả trả về để các bạn tiện so sánh.
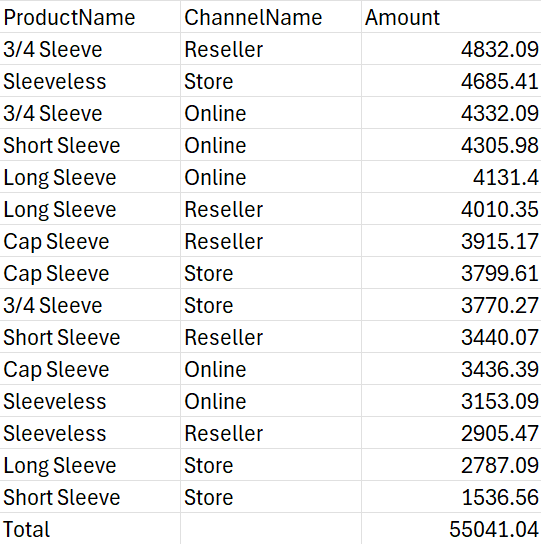
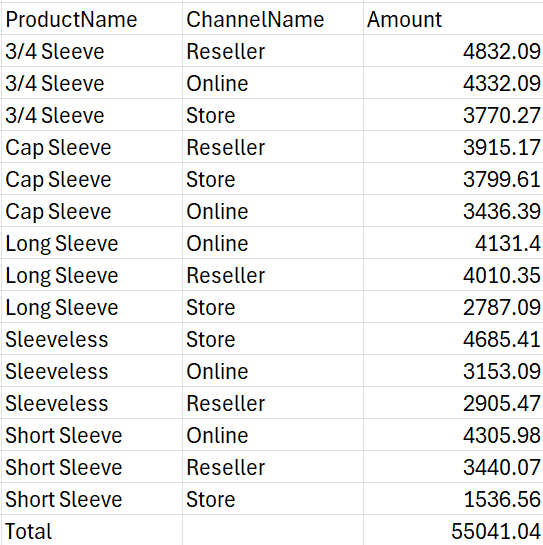
Cả 2 công thức trên đều nhóm dữ liệu theo 2 cột Product Name và Channel Name, sau đó sắp xếp cột Amount giảm dần.
Bạn có thể thấy khi sử dụng Table thì cột Amount đơn giản chỉ sắp xếp giảm dần thôi.
Còn nếu sử dụng mặc định là hệ thống phân cấp Hierarchy thì sẽ sắp xếp theo từng cặp Product Name tăng dần. Sau đó trong từng nhóm Product Name thì Amount mới được sắp xếp giảm dần.
Đâu là điểm khác biệt cơ bản của hệ thống phân cấp Hierarchy và Table.
Thực tế thì khi làm báo cáo các bạn sẽ luôn muốn sắp xếp theo 1 phân cấp nào đó nên việc sử dụng field_relationship là Hierarchy được sử dụng nhiều hơn so với Table.
Chính vì thế field_relationship = Hierarchy chính là mặc định của hàm GROUPBY.
Các bạn có thể thực hành với dữ liệu của Sheet GROUPBY_01 dưới đây
2.6. Sắp xếp dữ liệu theo cột Row Fields từ thứ 2 trở đi
Với tham số sort_order thì hàm GROUPBY luôn ưu tiên sắp xếp cột thứ 1 trước vì nó theo 1 hệ thống phân cấp các cột từ trái qua phải.
Vì vậy khi bạn muốn sắp xếp lấy cột Row Fields thứ 2 làm chuẩn thay vì cột thứ 1 thì ta sẽ làm như sau:
Và đây là kết quả trả về.

Bạn có thể thấy kết quả trả về của hàm GROUPBY đang sắp xếp theo cột ChannelName. Sau đó mới sắp xếp tang dần theo cột ProductName.
Trong bài toán trên nếu bạn muốn sắp xếp thêm Amount giảm dần thì bạn cũng có thể làm được như sau.
Và đây là kết quả trả về

Với cách viết thông qua hàm SORT để sắp xếp thì bạn có thể tuỳ biến rất dễ theo ý mình.
Các bạn có thể thực hành với dữ liệu của Sheet GROUPBY_01 dưới đây
2.7. Sử dụng tham số total_depth của hàm GROUPBY
Đối số total_depth của hàm GROUPBY gồm các giá trị đầu vào như sau:
+ 0 – No totals: Bạn sẽ không chèn vào SubTotal hay Grand Total cho kết quả của hàm GROUPBY.
+ 1 – Grand Totals: Bạn có thể hiểu là Grand Total Only cũng được. Có nghĩa là bạn sẽ chỉ chèn Grand Total thôi và không chèn SubTotal.
+ 2 – Grand and SubTotals: Bạn sẽ chèn vào cả Grand Total và SubTotal cho kết quả của hàm GROUPBY.
+ -1 – Grand Totals at Top: Bạn sẽ chèn Grand Total lên phía trên.
+ -2 – Grand and SubTotals at Top: Bạn sẽ chèn vào cả Grand Total và SubTotal lên phía trên.
Thực tế khi làm báo cáo các bạn sẽ chủ yếu sử dụng các đối số đầu vào là 0, 1, 2.
Còn việc bạn để các giá trị Grand Total và SubTotal ở bên trên là rất ít khi được sử dụng ở trong thực tế.
Giờ ta sẽ làm 1 ví dụ đơn giản hiển thị SubTotal cho từng Channel Name.
Bạn hãy lưu ý thêm 1 điều nữa đó là SubTotal chỉ áp dụng với cột đầu tiên của Row_Fields của hàm GROUPBY.
Và đây là kết quả trả về

Các bạn có thể thực hành với dữ liệu của Sheet GROUPBY_01 dưới đây
2.8. Sử dụng hàm ARRAYTOTEXT để tạo danh sách Email theo từng phòng ban
Giả sử ta có 1 khối dữ liệu như hình dưới đây.

Bạn muốn tạo ra 1 danh sách email theo từng phòng ban. Vậy bạn sẽ làm thế nào?
Với bài toán này nếu không có hàm GROUPBY thì bạn có thể viết kết hợp hàm UNIQUE và TEXTJOIN như sau.
Tuy nhiên khi đã có hàm GROUPBY thì bạn có thể sử dụng hàm GROUPBY và Function ARRAYTOTEXT của nó như sau.
Tuy nhiên hàm ARRAYTOTEXT mặc định sẽ nối các giá trị trong ARRAY lại bằng dấu “,” Nếu bạn muốn đổi sang dấu “;” để tiện copy vào email thì bạn viết lại như sau.
Chỉ cần sử dụng hàm SUBSTITUTE để thay thế dấu “,” thành dấu “;” là được.
Các bạn có thể thực hành với dữ liệu của Sheet GROUPBY_02 dưới đây
2.9. Ứng dụng ARRAYTOTEXT để tạo danh sách nhân viên theo phòng ban
Đây cũng là 1 bài toán rất đơn giản mà bạn có thể xử lý bằng ARRAYTOTEXT kết hợp với UNIQUE như sau

Đây là kết quả mà chúng ta thu được.

Bằng việc sử dụng LAMBDA kết hợp với ARRAYTOTEXT và UNIQUE bạn đã có được kết quả mà chúng ta cần.
Nếu không sử dụng phương án trên thì bạn có thể tham khảo công thức dưới đây.
Bạn sẽ thấy công thức này cũng ra kết quả tương tự nhưng bạn viết phức tạp hơn rất nhiều.

Bạn có thể thực hành với dữ liệu Sheet GROUPBY_03 dưới đây
2.10. Làm việc với dữ liệu ở dạng không chuẩn
Giả sử các bạn có 1 Data như sau.

Bạn có thể thấy đây là 1 dữ liệu không được chuẩn. Khi có sự xuất hiện Sub Total như Total Quarter 1 như hình trên.
Vậy nếu Data không chuẩn như vậy mà dùng GROUPBY thì có được không?
Câu trả lời là nếu để yên thì không. Bạn sẽ sử dụng filter_array để loại bỏ các dữ liệu này trước khi GROUPBY như sau.
Cột Y là cột chứa giá trị ngày tháng. Ta sử dụng công thức ISNUMBER để loại bỏ các giá trị không phải số trong cột ngày tháng. Chính là các giá trị SubTotal như Total Quarter 1.
Và đây là kết quả bạn nhận được.

Bạn có thể thực hành bằng dữ liệu Sheet GROUPBY_04 dưới đây
2.11. Tạo báo cáo xác định % doanh thu và tổng doanh số bằng hàm GROUPBY
Đầu tiên chúng ta sẽ học cách tạo ra cột % doanh thu thay vì Total Sales đã tính toán từ đầu bài viết tới đây đã.
Công thức mà bạn sẽ sử dụng ở đây sẽ là hàm PERCENTOF thay vì hàm SUM.
Và đây là kết quả bạn nhận được.

Vậy giờ bạn muốn có thêm cột Total Sales nữa thì có được không. Câu trả lời là hoàn toàn được. Ý tưởng ở đây là tạo ra 2 Array báo cáo 1 array chứa % Sale, 1 array chứa Total Sales. Sau đó ta dùng hàm XLOOKUP để dò tìm giá trị bên bảng Total Sales ghép vào với bảng % Sales để thu được kết quả mà bạn muốn. Cụ thể ta sẽ viết như sau.
Và đây là kết quả trả về.

Bạn có thể thực hành bằng dữ liệu Sheet GROUPBY_04 dưới đây
2.12. Tạo báo cáo theo từng bạn Sales theo từng tháng trong năm.
Đây là kết quả trả về của bài toán của chúng ta.

Như bạn thấy cột Month / Year dữ liệu trả về là kiểu chữ vì thế nếu muốn sắp xếp tăng dần theo từng tháng trong năm thì bắt buộc phải có 1 cột ngày tháng phía trước đó. Vì ngày tháng là dữ liệu kiểu số nên có thể sắp xếp tăng dần được.
Vậy nếu bạn muốn chỉ xuất ra kết quả có 3 cột như hình thì làm làm sao?
Rất đơn giản bạn chỉ cần DROP cột đó đi là được.
Và đây là công thức được mình sử dụng.
Bạn có thể thực hành bằng dữ liệu Sheet GROUPBY_04 dưới đây
2.13. GROUPBY sử dụng nhiều Function cùng lúc
Đây là 1 chức năng rất lạ của GROUPBY và không hề ghi trong bất kỳ tài liệu nào của Microsoft. Tuy nhiên nó vẫn hoạt động.
Về cơ bản bạn sẽ đưa các hàm bạn muốn sử dụng cùng lúc vào trong hàm HSTACK như dưới đây là được.
Và đây là kết quả trả về

Bạn có thể thực hành bằng dữ liệu Sheet GROUPBY_01 dưới đây
2.14. GROUPBY sử dụng Function PERCENTOF
Có 1 điều bắt buộc phải lưu ý khi sử dụng Function PERCENTOF đó là cột values được lựa chọn bắt buộc phải là kiểu số nếu không sẽ bị lỗi.
Ở đây ta có 1 Data như hình dưới đây.

Nhiệm vụ của bạn đó là đếm xem mỗi bạn Sales có bao nhiêu đơn hang, và số đơn hàng của bạn Sales đó chiếm bao nhiêu % trên tổng số đơn hàng.
Đây là công thức được mình sử dụng:
Mẹo ở đây đó là biến vùng values trong hàm GROUPBY thành 1 dãy toàn số 1 để tiện cho việc đếm hơn. Đó chính là lý do mình sử dụng cụm SEQUENCE(ROWS(C2:C38),,,0)
Và đây là kết quả trả về.

Tương tự nếu bạn muốn ghép thêm Total Sales và % Sales thì cũng tương tự như bài trên mình đã nói là được.
Và đây là kết quả trả về.

Bạn có thể thực hành bằng dữ liệu Sheet GROUPBY_05 dưới đây
Nói chung công thức trong Excel 365 có vô vàn sự kết hợp. Chỉ cần bạn nắm vững cách sử dụng từng hàm và ứng dụng đủ nhiều thì bạn có thể hoàn thiện được rất nhiều công thức khó cũng như tăng tốc công việc của bạn.

please authorize